«десь € постараюсь изложить основные операции предлагаемого поискового алгоритма. ќн несколько отличаетс€ от традиционного генетического алгоритма, как в построении символьной модели, так и в структуре самого алгоритма. ќб истории по€влени€ генетических алгоритмов и о том, дл€ каких задач они примен€ютс€ читайте в главе "ѕопул€рно о генетических алгоритмах".
«адача поиска
ѕрежде чем приступать к описанию поискового алгоритма, следует определитьс€ с тем, что мы будем понимать под задачей поиска.
ѕредполагаетс€, что целью задачи поиска €вл€етс€ нахождение объекта с некоторыми свойствами. ак правило, поиск производитс€ среди конечного (иногда и бесконечного) множества объектов (потенциальных решений).
ѕервый шаг при решении задачи поиска состоит в том, чтобы определитьс€ относительно объектов этого множества. “.е. нужно четко представл€ть себе класс исследуемых объектов. Ѕудем называть это множество объектов пространством объектов и обозначим его O. ѕримером O может служить пространство n-мерных векторов вещественных чисел, множество шахматных позиций или множество
вариантов раскройки ткани.
¬торой шаг, который должен предшествовать процедуре поиска состоит в выборе некоторого представлени€ объектов из пространства O. ѕредставление определ€етс€ множеством S - пространством представлений. S выбираетс€ с таким расчетом, что алгоритму поиска будет легче манипулировать членами S, чем O. ак правило, S не равно O, хот€ это и не всегда об€зательно.
¬ отличие от пространства объектов, пространство представлений об€зательно конечное. ¬ реальных задачах в реальном времени вместо O прин€то рассматривать его конечное подмножество O'. ќтображение между элементами O и S будет называть представлением. ѕредставление описывает св€зь между исследуемыми объектами, которые выступают в качестве потенциальных решений задачи поиска, и объектам, управлением и манипулированием которых занимаетс€ поисковый алгоритм. ѕредставление есть функци€ кодировани€
e: O -> S
ƒл€ o из O и s из S запись s=e(o) будет обозначать то, что s €вл€етс€ представлением o. ¬ общем случае e(o) может описывать целое множество представлений, однако этот случай нами не рассматриваетс€. ќбратное отношение будем записывать как e-1 (функци€ декодировани€)
e-1: S -> O
обратное отношение используетс€ тогда, когда по новому представлению s' из S, полученному в результате поиска, требуетс€ восстановить соответствующее ему решение o' из O.
e-1(o) может представл€ть множество объектов из O. ≈сли e(o') - не пустое множество, то будем говорить, что o' представлен. ≈сли e-1(s') - пустое множество, то s' - недопустимое представление.
»спользование представлений позвол€ет осуществл€ть поиск практически при минимуме информации о характере и свойствах пространства объектов. ак правило бывает достаточно только той информации, котора€ позвол€ет описать ландшафт в пространстве представлений.
—реди различных типов задачи поиска наибольший интерес дл€ нас представл€ет задача в которой требуетс€ найти лучший, на сколько это возможно при существующих ограничени€х (временных или каких-либо еще), объект o*. ѕри этом на множестве объектов O должна быть определена функци€ цели f(o), позвол€юща€ сравнивать решени€
f: O -> R
така€, чтобы дл€ любых двух o1,o2 из O, если f(o1)>f(o2), то
o1 считаетс€ решением лучше, чем o2. R - множество вещественных чисел. ќчевидно, что об оптимальности того или иного решени€ можно говорить лишь тогда, когда исследовано все пространство представлений S.
ƒл€ реализации алгоритма поиска в пространстве представлений можно ввести функцию оценки представлений, аналогично функции f, определенной на элементах из множества O. ќпределим ее как
m: S -> R
√де R - множество вещественных чисел.
— помощью m можно определить пор€док в S таким образом, чтобы представител€м лучших объектов в смысле f соответствовало большее значение m. “.е. если дл€ любых двух объектов o1, o2 из O в S определены различными представител€ми s1=e(o1) и
s2=e(o2), s1 не равно s2 и если f(o1)>f(o2), то m(s1)>m(s2). ¬ общем случае функцией face=Symbol>m(s) может быть люба€ функци€ M, удовлетвор€юща€ этому условию.
m(s) = M(f(e-1(s)))
ќднако, как правило, вполне достаточно сделать
m(s) = f(e-1(s))
»ногда, в зависимости от конкретных операторов алгоритма поиска, бывает необходимо, что функци€ m(s) принимала положительные значени€.
ѕредставленные рассуждени€ позвол€ют сформулировать задачу поиска наилучшего объекта o* из множества O следующим образом
o* = argmax f(e-1(s))
s из S
≈е решение осуществл€етс€ поиском в пространстве S оптимального представлени€ s*:
s* = argmax m(s)
s из S
≈ще раз, прежде чем построить поисковый алгоритм нужно определитьс€ с символьной моделью задачи, котора€ включает в себ€
пространство потенциальных решений O,
пространство представлений S,
функцию кодировани€ e и декодировани€ e-1,
функцию цели f,
функци€ оценки представлений m.
ѕостановка задачи
Ќами будет рассматриватьс€ обща€ задача непрерывной оптимизации
max f(x), где D = {x = (x1, x2, :, xN) | xi на [ai, bi], i=1, 2,:N}
x из D | (1) |
f(x) - максимизируема€ (целева€) скал€рна€ многопараметрическа€ функци€, котора€ может иметь несколько глобальных экстремумов, пр€моугольна€ область D - область поиска, D - подмножество RN.
ѕредполагаетс€, что о функции f(x) известно лишь то, что она определена в любой точке области D. Ќикака€ дополнительна€ информаци€ о характере функции и ее свойствах (дифференцируемость, липшицируемость, непрерывность и т.д.) не учитываетс€ в процессе поиска. ѕод решение задачи (1) будем понимать вектор x = (x1, x2, :, xN).
ќптимальным решением задачи (1) будем считать вектор x*, при котором целева€ функци€ f(x) принимает максимальное значение. »сход€ из предположени€ о возможной многоэкстремальности f(x), оптимальное решение может быть не единственным.
¬ прин€тых ранее обозначени€х под объектом будем понимать точку x в многопараметрическом пространстве O=D в RN. –оль функции цели будет играть максимизируема€ функци€ f(x).
—имвольна€ модель
ƒл€ того, чтобы построить пространство представлений под генетический алгоритм дл€ задачи непрерывной оптимизации, нужно помнить, что начина€ с 1975 - публикации первого издани€ книги √олланда - √ј-мы использовались при решении комбинаторных задачам оптимизации. »спользование аппарата дл€ решени€ дискретных задач применительно к задачам непрерывной оптимизации допускалось путем дискретизации пространства параметров скал€рной функции f(x), дл€ которой предсто€ло найти оптимальное решение.
ѕараметры x обычно кодируютс€ бинарной строкой s. »спользу€ целевую функцию f(x) можно построить функцию m(s) - функцию пригодности или, как она называетс€ в генетических алгоритмах, функци€ приспособленности, отобразив, когда это необходимо, f на положительную полуось. Ёто делаетс€ дл€ того, чтобы гарантировать пр€мое соотношение между значение целевой функции и приспособленностью решени€, и затем така€ модифицированна€ целева€ функци€ рассматриваетс€ как функци€ приспособленности √ј. “аким образом, каждое возможное решение s, имеющее соответствующую приспособленность m(s), представл€ет решение x.
ќбычно, переход из пространства параметров в хемминингово пространство бинарных строк осуществл€етс€ кодированием переменных x1, x2, :, xN в двоичные целочисленные строки достаточной длины - достаточной дл€ того, чтобы обеспечить желаемую точность. ∆елаема€ точность в этом случае и будет тем отправным условием, которое определ€ет длину бинарных строк. ƒл€ этого пространство параметров должно быть дискретизировано таким образом, чтобы рассто€ние между узлами дискретизации соответствовало требуемой точности. ѕредположим, по условию задачи с функцией от двух переменных x1 и x2, определенной на пр€моугольной области D = {0 1<1;†02<1}, требуетс€ локализовать решение x* с точностью по каждому из параметров 10-6. ƒл€ достижени€ такой точности пространство параметров дискретизуетс€ равномерной
сеткой с (bi-ai)/(10-6)= 1/10-6 = 1000000 узлами по каждой координате. «акодировать такое количество узлов можно l = 20 битами, где l определ€етс€ из услови€ 106 < 2l+1. ¬от и получаетс€, что обща€ длина бинарной строки кодировки дл€ двумерной задачи составит 2X20 = 40 бит.
ѕри таком способе кодировани€ значени€ варьируемых параметров решений будут располагатьс€ по узлам решетки, дискретизующей D. —оответственно, если кодировки двух решений будут совпадать, то будут совпадать и значени€ параметров обоих решений.
¬о многих случа€х така€, казалось бы, естественна€ модель может оказатьс€ неэффективной. роме того, что она достаточно громоздка (¬о что превратитс€ хемминингово пространство поиска дл€ задачи с сотней параметров?!), практика показывает, что длинна€ кодировка повышает веро€тность "преждевременной" сходимости, дл€ борьбы с которой изобретаютс€ различные уловки. тому же применение длинных кодировок вовсе не гарантирует, что найденное решение будет обладать требуемой точностью, поскольку этого, в принципе, не гарантирует сам √ј.
ћы представим модификацию символьной модели, позвол€ющей, не примен€€ длинных кодировок, добиватьс€ сравнимой точности.
»так, чтобы провести дискретизацию пространства D и закодировать каждое возможное решение строкой s, как и прежде "погрузим" равномерную сетку в пространство параметров. ƒл€ этого проделаем следующее.
аждый интервал [ai, bi] разбиваем на k отрезков равной длины:
hi = (bi - ai) / k,††i = 1, 2, :N.
Ётом самым покроем i-ый интервал [ai, bi] сетью si из (k+1) узла с посто€нным шагом hi.
xi,j = ai + j.hi,††j = 0, 1, : k.
»спользу€ двоичный алфавит {0,1} каждому узлу сетки si можно присвоить уникальный бинарный код длины q. ƒлина кода q выбираетс€ таким образом, чтобы k < 2q. Ќаиболее целесообразно и экономично использовать сетку с k = 2q-1.
“огда символьна€ запись j-ого узла по i-ой координатной оси в двоичном коде можно представить в виде следующей бинарной конструкции
ѕровед€ дискретизацию по всем N координатным ос€м, получим в N-мерном параллелепипеде D пространственную решетку S с (k+1)N узлом, где каждый узел s можно представить в виде линейной последовательности таких записей (хромосом).
| s = | b11 | b21 | ... | bq1 | ... | b1N | b2N | ... | bqN |
“аким образом, чтобы построить символьную модель непрерывной оптимизационной задачи на гиперкубе D нужно представить множество узлов пространственной решетки S с помощью бинарных последовательностей (хромосом).
√ј оперирует строками фиксированной длины.
„тобы примен€ть √ј к задаче, сначала выбираетс€ метод кодирование решений в виде строки. ‘иксированна€ длина (l-бит, l=q*N) двоичной кодировки означает, что люба€ из 2l возможных бинарных строк представл€ет возможное решение задачи.
ѕо существу, така€ кодировка соответствует разбиению пространства параметров на гиперкубы, которым соответствуют уникальные комбинации битов в строке - хромосоме. ƒл€ установлени€ соответстви€ между гиперкубами разбиени€ области и бинарными строками, описывающими номера таких гиперкубов, кроме обычной двоичной кодировки использовалс€ рефлексивный код √ре€. од √ре€ предпочтительнее обычного двоичного тем, что обладает свойством непрерывности бинарной комбинации: изменение кодируемого числа на единицу соответствует изменению кодовой комбинации только в одном разр€де.
»де€ √ј состоит в том, чтобы манипулиру€ имеющейс€ совокупностью бинарных представлений, с помощью р€да генетических операторов получать новые строки, т.е. перемещатьс€ в новые гиперкубики. ѕолучив бинарную комбинацию дл€ нового решени€, формируетс€ вектор (операци€ декодировани€ e-1), со значени€ми из соответствующего гиперкуба, использу€ равномерное распределение.
“аким образом, каждое решение генетического алгоритма будет иметь следующую структуру:
“очка в пространстве параметров (фенотип):
x = (x1, x2, : xN) принадлежит D из RN;
Ѕинарна€ строка s фиксированной длины, однозначно идентифицирующа€ гиперкуб разбиени€ пространства параметров (генотип):
s = (b1, b2, :, bl)
принадлежит S,
где S - пространство представлений - бинарных строк длины l.
—кал€рна€ величина m, соответствующа€ значению целевой функции в точке х (приспособленность):
m = f(x).
¬ терминологии, прин€той в теории √ј, такую структуру прин€то называть особью. ѕредлагаема€ модель об€зательно включает в себ€ вектор со значени€ми из гиперкуба пространства параметров. —овокупность особей прин€то называть попул€цией.
—имвольна€ модель, предлагаемых ранее генетических алгоритмов, предусматривала дискретизацию пространства параметров с шагом, соответствующим требуемой точности. ѕри этом решением задачи (1) мог быть только узел пространственной решетки, так что между точкой в параметрическом пространстве и ее представителем в пространстве S существовало взаимно однозначное соответствие. ѕредлагаема€ же нами модель не предусматривает однозначности, допуска€ существование целого множества решений, имеющих единого представител€. ¬ терминологии √ј это означает, что могут существовать особи, обладающие различными фенотипическими признаками, но имеющие одинаковые генотипы (такое €вление, вообще говор€, встречаетс€ в природе, например, у одно€йцовых близнецов). Ёто позвол€ет использовать более крупное разбиение пространства параметров, сужа€ пространство бинарных строк S и дела€ при этом длину хромосомного набора короче. ћногообразие точек, распредел€емых в небольших гиперкубиках, позвол€ет достигать высокой точности даже в тех задачах, где решение не попадает в окрестность узла решетки.
¬ключение в символьную модель вектора со значени€ми из пространства параметров может показатьс€ избыточным, однако, така€ модель предоставл€ет исследователю больше свободы с манипулированием представлени€, в частности ниже будут рассмотрены вопросы, св€занные с динамическим изменением длины кодировки на различных этапа поиска без потери лучших найденных решений.
√еометрическа€ интерпретаци€ символьной модели
»так, мы определись с тем, каким образом будет осуществл€тьс€ переход из евклидова пространства параметров в пространство представлений (бинарных строк). ƒавайте рассмотрим эту процедуду на конкретном примере простой одномерной функции f(x).
f(x) = 10 + x sin(x),
определенной на отрезке [0, 10].
ѕусть кодирование будет осуществл€тьс€ бинарными строками длины 3. “.е. отрезок [0,10] нужно разбить на 23 = 8 подинтервалов, каждому из которых будет соответствовать уникальна€ двоична€ комбинаци€, получаема€ переводом номера подинтервала, счита€ слева направо, в двоичную системы. ƒлина каждого такого интервала будет h=10:8=1.25.
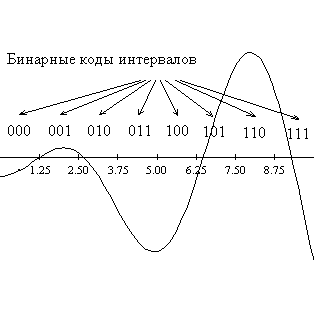 |
–исунок 1: ѕостроение символьной модели дл€ одномерной задачи, использу€ трехбитовое представление.
ѕространством поиска, таким образом, становитс€ множество всех бинарных строк длины 3. Ёто пространство можно представить в виде трехмерного куба, вершинам которого соответствуют кодовые комбинации, расставленные так, что хэмминингово рассто€ние между смежными вершинами равно 1.
–исунок 2: ѕространство поиска дл€ трехбитового представлени€.
«адача алгоритма поиска заключаетс€ в том, чтобы, следу€ некоторому правилу, перемещатьс€ в новые вершины этого куба, что будет соответствовать исследованию новых подинтервалов в пространстве D.
Ўима (schema)
’от€ внешне кажетс€, что √ј обрабатывает строки, на самом деле при этом не€вно происходит обработка шим, которые представл€ют шаблоны подоби€ между строками (√ольдберг, 1989; √олланд, 1992). √ј практически не может заниматьс€ полным перебором всех представлений в пространстве поиска. ќднако он может производить выборку значительного числа гиперплоскостей в област€х поиска с высокой приспособленностью. ажда€ така€ гиперплоскость соответствует множеству похожих строк с высокой приспособленностью.
Ўима - это строка длины l (что и длина любой строки попул€ции), состо€ща€ из знаков алфавита {0;1;*}, где {*} - неопределенный символ. ажда€ шима определ€ет множество всех бинарных строк длины l, имеющих в соответствующих позици€х либо 0, либо 1, в зависимости от того, какой бит находитс€ в соответствующей позиции самой шимы. Ќапример, шима, 10**1, определ€ет собой множество из четырех п€тибитовых строк {10001; 10011; 10101; 10111}. ” шим выдел€ют два свойства - пор€док и определенна€ длина.
ѕор€док шимы - это число определенных битов ("0" или "1") в шиме.
ќпределенна€ длина - рассто€ние между крайними определенными битами в шиме. Ќапример, вышеупом€нута€ шима имеет пор€док o(10**1)=3, а определенна€ длина d(10**1) = 4. ажда€ строка в попул€ции €вл€етс€ примером 2l шим.
¬ернемс€ к нашему примеру с одномерной функцией f(x)=10+x*sin(x) и 3-битными строками. ћы уже говорили, что пространство поиска в этом случае будет трехмерным кубом. ƒавайте посмотрим, какую графическую интерпретацию получат шимы.
—начала исследуем шимы, чей пор€док равен трем, т.е. все три бита в шаблоне определены. ѕон€тно, таких шим - всех бинарные комбинации длины 3. Ќетрудно сделать вывод, что в данном случае шимы пор€дки 3 будут соответствовать вершинам куба.
“еперь давайте посмотрим, чему буду соответствовать шаблоны пор€дка 2. “аких шим 2o(H)Cll-o(H) = 22C31 = 12: {00*, 01*, 10*, 11*, 0*0, 0*1, 1*0, 1*1, *00, *01, *10, *11}. √еометрически, все такие шаблоны описывают поверхности, размерность которых на единицу превосходит размерность точки - вершины куба, т.е. шимы пор€дка 2 длины 3 соответствуют ребрам куба. Ќиже приводитс€ графическа€ интерпретаци€ шим H=(00*) и H=(*10).
–исунок 2: √еометрическа€ интерпретаци€ шаблонов пор€дка 2.
“очно также можно показать, чему соответствуют шаблоны, чей пор€док равен 1. “аких шим 6: {0**, 1**, *0*, *1*, **0, **1}. ¬се они представл€ют поверхности, размерность которых на единицу больше размерности шим пор€дка 2, т.е. в нашем случае это грани куба. ¬от, например, как выгл€д€т шимы H=(**1) и H=(0**).
–исунок 3: √еометрическа€ интерпретаци€ шаблонов пор€дка 1.
≈сли же рассматривать единственную шиму пор€дка 0, т.е. в ней нет определенных битов, то очевидно, что ее будет соответствовать весь куб.
ƒо сих про мы рассматривали то, как шимы представлены в пространстве бинарных строк. ј чему они будут соответствовать в евклидовом пространстве параметров? „тобы ответить на этот вопрос давайте вспомним, как мы вводили функцию кодировани€ и каким образом осуществл€ли переход в пространство представлений. Ќа примере одномерной функции это выгл€дело так: отрезок [a,b] разбивалс€ на 2l подинтервалов равной длины и каждый такой интервал кодировалс€ бинарной последовательностью (см. –исунок 1). ѕоскольку мы говорили, что кажда€ шима определ€ет множество всех бинарных строк, имеющих в соответствующих позици€х либо 0, либо 1, в зависимости от того, какой бит находитс€ в соответствующей позиции самой шимы, то в пространстве параметров шиме будет соответствовать объединение подинтервалов, бинарные представлени€ которых €вл€ютс€ примерами этой шимы. Ќапример, в рассматриваемой нами задаче шимам H=(00*)и H=(*10) на отрезке [0,10] будут соответствовать следующие области (на рисунке они выделены темным цветом).
–исунок 4: »нтерпретаци€ шим пор€дка 2 в пространства параметров.
Ўимы с меньшим пор€дком будут задавать более многочисленное множество бинарных строк, поэтому в пространстве параметров они смогут охватить большую область. ¬от, например, как будут представлены шимы пор€дка 1 на нашем примере.
–исунок 5: »нтерпретаци€ шим пор€дка 1 в пространства параметров.
—тро€щие блоки
—тро€щие блоки (Goldberg, 1989c) - это шимы обладающие:
высокой приспособленностью,
низким пор€дком,
короткой определенной длиной.
ѕриспособленность шимы определ€етс€ как среднее приспособленностей примеров, которые ее содержат.
ѕосле процедуры отбора остаютс€ только строки с более высокой приспособленностью. —ледовательно строки, которые €вл€ютс€ примерами шим с высокой приспособленностью, выбираютс€ чаще. россовер реже разрушает шимы с более короткой определенной длиной, а мутаци€ реже разрушает шимы с низким пор€дком. ѕоэтому, такие шимы имеют больше шансов переходить из поколени€ в поколение. √олланд (1992) показал, что, в то врем€ как √ј €вным образом обрабатывает n строк на каждом поколении, в тоже врем€ не€вно обрабатываютс€ пор€дка n3 таких коротких шим низкого пор€дка и с высокой приспособленностью (полезных шим, "useful schemata"). ќн называл это €вление не€вным параллелизмом. ƒл€ решени€ реальных задач, присутствие не€вного параллелизма означает, что больша€ попул€ци€ имеет больше возможностей локализовать решение экспоненциально быстрее попул€ции с меньшим числом особей.
–абота простого √ј
»меютс€ много способов реализации идеи биологической эволюции в рамках √ј. “радиционным считаетс€ √ј, представленный на схеме.
Ќј„јЋќ /* простой генетический алгоритм*/
—оздать начальную совокупность структур (попул€цию) ќценить каждую структуру
останов := FALSE
ѕќ ј Ќ≈ останов ¬џѕќЋЌя“№
Ќј„јЋќ /* нова€ итераци€ (поколение)
ѕрименить оператор отбора
ѕќ¬“ќ–»“№ (размер_попул€ции/2) –ј«
Ќј„јЋќ /* цикл воспроизводства */
¬ыбрать две структуры (родители) из множества предыдущей итерации
ѕрименить оператор скрещивани€ с заданной веро€тность к
выбранным структурам и получить две новые структуры (потомки)
ќценить эти новые структуры
≈сли оператор скрещивани€ не примен€етс€,
то потомки станов€тс€ копи€ми своих родителей
ѕоместить потомков в новое поколение
ќЌ≈÷
ѕрименить оператор мутации с заданной веро€ностью
≈—Ћ» попул€ци€ сошлась “ќ останов := TRUE
ќЌ≈÷
ќЌ≈÷
ѕростой √ј случайным образом генерирует начальную совокупность (попул€цию) структур (особей). –абота √ј представл€ет собой итерационный процесс, который продолжаетс€ до тех пор, пока не выполн€тс€ заданное число поколений или какой-либо иной критерий остановки. Ќа каждом поколении √ј реализуетс€ отбор пропорционально приспособленности, одноточечный оператор кроссовера и оператор мутации. —начала, пропорциональный отбор назначает каждой структуре веро€тность Ps(i) равную отношению ее приспособленности к суммарной приспособленности попул€ции.
«атем происходит отбор (с замещением) всех n структур дл€ дальнейшей генетической обработки, согласно величине Ps(i). ѕростейший пропорциональный отбор - рулетка (roulette-wheel selection, Goldberg, 1989c) - отбирает особей с помощью n "запусков" рулетки. олесо рулетки содержит по одному сектору дл€ каждого члена попул€ции. –азмер i-ого сектора пропорционален соответствующей величине Ps(i). ѕри таком отборе члены попул€ции с более высокой приспособленностью с большей веро€тность будут чаще выбиратьс€, чем особи с низкой приспособленностью.
ѕосле отбора, n выбранных особей подвергаютс€ кроссоверу (иногда называемому рекомбинацией) с заданной веро€тностью Pc. n строк случайным образом разбиваютс€ на n/2 пары. ƒл€ каждой пары с веро€тность Pc может примен€тьс€ кроссовер. —оответственно с веро€тностью 1-Pc кроссовер не происходит и неизмененные особи переход€т на стадию мутации. ≈сли кроссовер происходит, полученные потомки замен€ют собой родителей и переход€т к мутации.
ќдноточечный кроссовер работает следующим образом. —начала, случайным образом выбираетс€ одна из l-1 точек разрыва. (“очка разрыва - участок между соседними битами в строке.) ќбе родительские структуры разрываютс€ на два сегмента по этой точке. «атем, соответствующие сегменты различных родителей склеиваютс€ и получаютс€ два генотипа потомков.
Ќапример, предположим, один родитель состоит из 10 нолей, а другой - из 10 единиц. ѕусть из 9 возможных точек разрыва выбрана точка 3. –одители и их потомки показаны ниже.
| | | | россовер | | | | –одитель 1 | 0000000000 | 000~0000000 | -> | 111~0000000 | 1110000000 | ѕотомок 1 | –одитель 2 | 1111111111 | 111~1111111 | -> | 000~1111111 | 0001111111 | ѕотомок 2 |
ѕосле того, как закончитс€ стади€ кроссовера, выполн€ютс€ операторы мутации. ¬ каждой строке, котора€ подвергаетс€ мутации, каждый бит с веро€тностью Pm измен€етс€ на противоположный. ѕопул€ци€, полученна€ после мутации записывает поверх старой и этим цикл одного поколени€ завершаетс€. ѕоследующие поколени€ обрабатываютс€ таким же образом: отбор, кроссовер и мутаци€.
¬ насто€щее врем€ исследователи √ј предлагают много других операторов отбора, кроссовера и мутации. ¬от лишь наиболее распространенные из них. ѕрежде всего, турнирный отбор (Brindle, 1981; Goldberg и Deb, 1991). “урнирный отбор реализует n турниров, чтобы выбрать n особей. аждый турнир построен на выборке k элементов из попул€ции, и выбора лучшей особи среди них.
Ќаиболее распространен турнирный отбор с k=2.
Ёлитные методы отбора (De Jong, 1975) гарантируют, что при отборе об€зательно будут выживать лучший или лучшие члены попул€ции совокупности. Ќаиболее распространена процедура об€зательного сохранени€ только одной лучшей особи, если она не прошла как другие через процесс отбора, кроссовера и мутации. Ёлитизм может быть внедрен практически в любой стандартный метод отбора.
ƒвухточечный кроссовер (Cavicchio, 1970; Goldberg, 1989c) и равномерный кроссовер (Syswerda, 1989) - вполне достойные альтернативы одноточечному оператору. ¬ двухточечной кроссовере выбираютс€ две точки разрыва, и родительские хромосомы обмениваютс€ сегментом, который находитс€ между двум€ этими точками. ¬ равномерном кроссовере, каждый бит первого родител€ наследуетс€ первым потомком с заданной веро€тностью; в противном случае этот бит передаетс€ второму потомку. » наоборот.
“еорема шим
“ак почему же генетический алгоритм работает и локализует области с высокой приспособленностью? аким образом теори€ шим или шаблонов подоби€ про€вл€етс€ в работе √ј? ƒл€ того, чтобы ответить на эти вопросы и чтобы дать представление о внутренних механизмах работы считаю необходимым кратко изложить основную теорему генетических алгоритмов, известную как "теорема шим". ќна показывает, каким образом простой √ј экспоненциально увеличивает число примеров полезных шим или стро€щих блоков, что приводит к нахождению решени€ исходной задачи.
ѕусть m(H,t) - число примеров шимы H в t-ом поколении. ¬ычислим ожидаемое число примеров H в следующем поколении или m(H,t+1) в терминах m(H,t). ѕростой √ј каждой строке ставит в соответствие веро€тность ее "выживани€" при отборе пропорционально ее приспособленности. ќжидаетс€, что шима H может быть выбрана m(H,t)*(f(H)/fср.) раз, где fср. - средн€€ приспособленность попул€ции, а f(H) - средн€€ приспособленность тех строк в попул€ции, которые €вл€ютс€ примерами H.
¬еро€тность того, что одноточечный кроссовер разрушит шиму равна веро€тности того, что точка разрыва попадет между определенными битами. ¬еро€тность же того, что H "переживает" кроссовер не меньше 1-Pc*(d(H)/l-1). Ёта веро€тность - неравенство, поскольку шима сможет выжить, если в кроссовере участвовал также пример похожей шимы. ¬еро€тность того, что H переживет точечную мутацию - (1-Pm)o(H),это выражение можно аппроксимировать как (1-o(H)) дл€ малого Pm и o(H). ѕроизведение ожидаемого число отборов и веро€тностей выживани€ известно как теорема шим:
“еорема шим показывает, что стро€щие блоки растут по экспоненте, в то врем€ шимы с приспособленностью ниже средней распадаютс€ с той же скоростью.
Goldberg (1983, 1989c), в своих исследовани€х теоремы шим, выдвигает гипотезу стро€щих блоков, котора€ состоит в том, что "стро€щие блоки объедин€ютс€, чтобы сформировать лучшие строки". “о есть рекомбинаци€ и экспоненциальный рост стро€щих блоков ведет к формированию лучших стро€щих блоков.
¬ то врем€ как теорема шим предсказывает рост примеров хороших шим, сама теорема весьма упрощенно описывает поведение √ј. ѕрежде всего, f(H) и fср. не остаютс€ посто€нными от поколени€ к поколению. ѕриспособленности членов попул€ции знаменательно измен€ютс€ уже после нескольких первых поколений. ¬о-вторых, теорема шим объ€сн€ет потери шим, но не по€вление новых. Ќовые шимы часто создаютс€ кроссовером и мутацией. роме того, по мере эволюции, члены попул€ции станов€тс€ все более и более похожими друг на друга так, что разрушенные шимы будут сразу же восстановлены. Ќаконец, доказательство теоремы шим построено на элементах теории веро€тности и следовательно не учитывает разброс значений, в многих интересных задачах, разброс значений приспособленности шимы может быть достаточно велик, дела€ процесс формировани€ шим очень сложным (Goldberg и Rudnick, 1991; Rudnick и Goldberg, 1991). —ущественна€ разница приспособленности шимы может привести к сходимости к неоптимальному решению.
Ќесмотр€ на простоту, теорема шим описывает несколько важных аспектов поведени€ √ј. ћутации с большей веро€тностью разрушают шимы высокого пор€дка, в то врем€ как кроссовера с большей веро€тность разрушают шимы с большей определенной длиной. огда происходит отбор, попул€ци€ сходитс€ пропорционально отношению приспособленности лучшей особи, к средней приспособленности в попул€ции; это отношение - мера давлени€ отбора ("selection pressure", Back, 1994). ”величение или Pc, или Pm, или уменьшении давлени€ отбора, ведет к увеличенному осуществлению выборки или исследованию пространства поиска, но не позвол€ет использовать все хорошие шимы, которыми располагает √ј. ”меньшение или Pc, или Pm, или увеличение давлени€ выбора, ведет к улучшению использовани€ найденных шим, но тормозит исследование пространства в поисках новых хороших шим. √ј должен поддержать тонкое равновесие между тем и другим, что обычно известно как проблема "баланса исследовани€ и использовани€".
Ќекоторые исследователи критиковали обычно быструю сходимость √ј, за€вл€€, что испытание огромных количеств перекрывающихс€ шим требует большей выборки и более медленной, более управл€емой сходимости. ¬ то врем€ как увеличить выборку шим можно увеличив размер попул€ции (Goldberg, Deb, и Clark, 1992; Mahfoud и Goldberg, 1995), методологи€ управлени€ сходимость простого √ј до сих пор не выработана.
јлгоритм
ѕредлагаемый в нашей работе √ј сохран€ет основные принципы теории эволюционно-генетического поиска: процесс поиска оптимального решени€ описываетс€ итерационным процессом моделируемой "эволюции", целью которой €вл€етс€ нахождение одной или нескольких структур (особей), имеющей максимальную приспособленность, т.е. структуру, соответствующей оптимальному значению управл€емых параметров. ќднако реализацию данного генетического алгоритма отлична от традиционной схемы
Ќј„јЋќ /* генетический алгоритм */
/* формирование начальной совокупности решений P0 ={aK0}*/
сгенерировать начальную совокупности строк S0
сформировать векторы начального множества решений
X0=e-1(S0)
оценить начальные решени€ P0: m (S0)
t = 0 /* счетчик итераций */
/* процедура поиска */
ѕќ ј Ќ≈ выполнено услови€ останова ѕќ¬“ќ–»“№
Ќј„јЋќ
Rt=Pt/* репродукционное множество */
ƒЋя p = 1 до p = Np ѕќ¬“ќ–»“№
Ќј„јЋќ
выбрать ait и ajt из Pt:
ait, ajt =
B(Pt)
s2p-1t+1/2, s2pt+1/2 = —(ait,ajt)
x2p-1t+1/2 = e-1(s2p-1t+1/2)
x2pt+1/2 = e-1(s2pt+1/2)
оценить новые решени€ a2p-1t+1/2 и a2pt+1/2:
m(s2p-1t+1/2) и m(s2pt+1/2)
Rt = Rt U {a2p-1t+1/2,a2pt+1/2}
ќЌ≈÷
— веро€тность Pm дл€ каждого решени€ (k=1,2,:) ѕќ¬“ќ–»“№
Ќј„јЋќ
s2Np+kt+1/2 = M(am), am из Rt
x2Np+kt+1/2 = e-1(s2Np+kt+1/2)
оценить новое решение a2Np+kt+1/2: m(s2Np+kt+1/2)
Rt = Rt U {a2Np+kt+1/2}
ќЌ≈÷
ќператор отбора S: Rt -> Pt+1
t = t+1
ќЌ≈÷
ќЌ≈÷
ѕрежде всего отличие от классических √ј-мов состоит в сохранении вещественных векторов решений. ¬торым важным отличием €вл€етс€ пор€док реализации основных генетических операторов. ¬начале проходит стади€ "воспроизводства" новых решений, включающа€ в себ€ три элемента:
¬ыбор элементов ait и ajt (брачна€ пара), использу€ правило B /breeding/.
√енераци€ новых решений с помощью оператора "кроссовер" C /crossover/
Ћокальные изменени€ большого числа решений с помощью оператора "мутации" M /mutation/.
» лишь затем осуществл€етс€ процедура построени€ совокупность решений дл€ следующей итерации ("поколени€") из всего множества доступных к тому моменту решений - оператор S.
¬-третьих, представленный алгоритм, относитс€ скорее к так называемым "поколенческим" (термин ƒеянга) эволюционным алгоритмам, в которых эволюци€ идет от одной итерации к другой, допуска€ по€вление k>>1 новых решений, накапливаемых в репродукционном множестве, прежде, чем включитс€ процесс отбора, отбрасывающий лишние k решений.
ѕоскольку алгоритм построен таким образом, что решени€, получаемые в результате кроссовера, не замен€ют собой "родителей" (как в традиционном √ј), то такой параметр как Pc - веро€тность кроссовера - в данном случае не нужен (или всегда равен 1.0). ¬место него мы пользуемс€ параметром, описывающим число брачных пар. ”правл€ть количеством вычислений целевой функции, т.е. количеством генерируемых решений предпочтительнее этим детерминированным параметром.
Ќа каждом из этапов предлагаютс€ альтернативные генетические операторы. Ќекоторые из них уже известны и описаны в литературе (Mitchell, 1996), по€вление других обусловлено новизной символьной модели. ¬се они по-разному вли€ют на поведение √ј. ѕодробнее к этому вопросу мы еще вернемс€. ј пока, € еще раз остановлюсь на списке основных параметров √ј:
мощность множества решений Pt(численность попул€ции),
длина бинарных кодировок s(длина генотипов),
количество решений, генерируемых на каждой итерации,
веро€тность применени€ оператора локального изменени€ решений (мутации) M,
правило B выбора двух решений,
тип используемого оператора глобального поиска (кроссовера) —,
тип используемой оператора локального изменени€ (мутации) ћ,
процедура отбора S.
ѕочти все из них (кроме численности попул€ции) могут динамически измен€тьс€ от итерации к итерации.
ќчевидно, что восемь параметров - это достаточно много дл€ алгоритма. “о, насколько удачным окажетс€ применение √ј при решении той или иной задачи, во многом будет определ€тьс€ их удачной настройкой. ¬ообще говор€, строгих правил, универсальных дл€ всех задач, нет и быть не может (по теореме "не бывает бесплатных обедов" /"no free lunch" theorem, Wolpert & McReady, 1995/), однако в данной работе мы постараемс€ сформулировать некоторые рекомендации по настройке параметров дл€ решени€ определенного класса задач.
» последнее замечание. ѕоскольку предлагаемый генетический алгоритм отличаетс€ от других, разумно было бы условитьс€ сравнивать √ј по "алгоритмонезависимым" признакам. —равнение по числу итераций (поколений) мне представл€етс€ неуместным, поскольку эта характеристика скорее относитс€ к свойствам алгоритма, а не к качеству получаемых решений. Ќаибольший интерес, конечно же, представл€ет задача минимизации числа оценок целевой функции при соблюдении требуемой точности. » именно эту характеристику мы считаем определ€ющей при вынесении вердикта о том, насколько пригоден или непригоден √ј дл€ решени€ той или иной задачи. ћы исходим из предположени€, что раз √ј-мы создаютс€ дл€ решени€ реальных задач, то основное врем€ поиска решени€ должно складыватьс€ из оценок реальной модели (мощность газовой турбины или ситуаци€ на фондовом рынке), возможно путем проведени€ дорогосто€щих испытаний, а ускорить работу самого алгоритма можно гораздо проще, например использу€ вычислительную систему помощнее.
≈сли у ¬ас есть замечани€, предложени€ или пожелани€ относительно представленного здесь материала - просьба св€затьс€ с автором.
»саев —ергей
8 8 8
| |
















