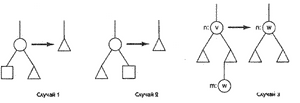Включение элементов
Для включения нового элемента в двоичное дерево поиска вначале нужно определить его точное положение - а именно внешний узел, который должен быть заменен путем отслеживания пути поиска элемента, начиная с корня. Кроме сохранения указателя n на текущий узел мы будем хранить указатель р на предка узла n. Таким образом, когда n достигнет некоторого внешнего узла, р будет указывать на узел, который должен стать предком нового узла. Для осуществления включения узла мы создадим новый узел, содержащий новый элемент, и затем свяжем предок р с этим новым узлом (рис. 3).
Компонентная функция insert включает элемент val в это двоичное дерево поиска:
Рис. 3: Включение элемента в двоичное дерево поиска
template void SearchTree::insert(T val)
{
if (root == NULL) {
root = new TreeNode(val);
return;
} else {
int result;
TreeNode *p, *n = root;
while (n) {
p = n;
result = (*cmp) (val, p->val);
if (result < 0)
n = p->_lchild;
else if (result > 0)
n = p->_rchild;
else
return;
}
if (result < 0)
p->_lchild = new TreeNode(val);
else
p-> rchild = new TreeNode(val);
}
}
Удаление элементов
Удаление элемента из двоичного дерева поиска гораздо сложнее, чем включение, поскольку может быть значительно изменена форма дерева. Удаение узла, у которого есть не более чем один непустой потомок, является равнительно простой задачей - устанавливается ссылка от предка узла на потомок. Однако ситуация становится гораздо сложнее, если у подлежащего удалению узла есть два непустых потомка: предок узла может быть связан с одним из потомков, а что делать с другим? Решение может заключаться не в удалении узла из дерева, а скорее в замене элемента, содержащегося в нем, на последователя этого элемента, а затем в удалении узла, содержащего этот последователь.
Рис. 4: Три ситуации, возникающие при удалении элемента из двоичного дерева поиска
Чтобы удалить элемент из дерева поиска, вначале мы отслеживаем путь поиска элемента, начиная с корня и вниз до узла n, содержащего элемент. В этот момент могут возникнуть три ситуации, показанные на рис. 4:
Узел n имеет пустой левый потомок. В этом случае ссылка на n (записанная в предке n, если он есть) заменяется на ссылку на правого потомка n.
У узла n есть непустой левый потомок, но правый потомок пустой. В этом случае ссылка вниз на n заменяется ссылкой на левый потомок узла n.
Узел n имеет два непустых потомка. Найдем последователя для n (назовем его m), скопируем данные, хранящиеся в m, в узел n и затем рекурсивно удалим узел m из дерева поиска.
Очень важно проследить, как будет выглядеть результирующее двоичное дерево поиска в каждом случае. Рассмотрим случай 1. Если подлежащий удалению узел n, является левым потомком, то элементы, относящиеся к правому поддереву n будут меньше, чем у узла р, предка узла n. При удалении узла n его правое поддерево связывается с узлом р и элементы, хранящиеся в новом левом поддереве узла р конечно остаются меньше элемента в узле р. Поскольку никакие другие ссылки не изменяются, то дерево остается двоичным деревом поиска. Аргументы остаются подобными, если узел n является правым потомком, и они тривиальны, если n - корневой узел. Случай 2 объясняется аналогично. В случае 3 элемент v, записанный в узле n, перекрывается следующим большим элементом, хранящимся в узле m (назовем его w), после чего элемент w удаляется из дерева. В получающемся после этого двоичном дереве значения в левом поддереве узла n будут меньше w, поскольку они меньше v. Более того, элементы в правом поддереве узла n больше, чем w, поскольку (1) они больше, чем v, (2) нет ни одного элемента двоичного дерева поиска, лежащего между v и w и (3) из них элемент w был удален.
Заметим, что в случае 3 узел m должен обязательно существовать, поскольку правое поддерево узла n непустое. Более того, рекурсивный вызов для удаления m не может привести к срыву рекурсивного вызова, поскольку если узел m не имел бы левого потомка, то был бы применен случай 1, когда его нужно было бы удалить.
На рис. 5 показана последовательность операций удаления, при которой возникают все три ситуации. Напомним, что симметричный обход каждого дерева в этой последовательности проходит все узлы в возрастающем порядке, проверяя, что в каждом случае это двоичные деревья поиска.
Компонентная функция remove является общедоступной компонентной функцией для удаления узла, содержащего заданный элемент. Она обращается к собственной компонентной функции _remove, которая выполняет фактическую работу:

Рис. 5: Последовательность операций удаления элемента: (а) и (б) - Случай 1: удаление из двоичного дерева элемента 8; (б) и (в) - Случай 2: удаление элемента 5; (в) и (г) - Случай 3: удаление элемента 3
template void SearchTree::remove(Т val)
{
_remove(val, root);
}
template
void SearchTree::_remove(Т val, TreeNode * &n)
{
if (n == NULL)
return;
int result = (*cmp) (val, n->val);
if (result < 0)
_remove(val, n->_lchild);
else if (result > 0)
_remove (val, n->_rchild);
else { // случай 1
if (n->_lchild == NULL) {
TreeNode *old = n;
n = old->_rchild;
delete old;
}
else if (n->_rchild == NULL { // случай 2
TreeNode *old = n;
n = old->_lchild;
delete old;
}
else { // случай 3
TreeNode *m = _findMin(n->_rchild);
n->val = m->val;
remove(m->val, n->_rchild);
}
}
}
Параметр n (типа ссылки) служит в качестве псевдонима для поля ссылки, которое содержит ссылку вниз на текущий узел. При достижении узла, подлежащего удалению (old), n обозначает поле ссылки (в предке узла old), содержащее ссылку вниз на old. Следовательно команда n=old->_rchild заменяет ссылку на old ссылкой на правого потомка узла old.
Компонентная функция removeMin удаляет из дерева поиска наименьший элемент и возвращает его:
template Т SearchTree::removeMin (void)
{
Т v = findMin();
remove (v);
return v;
}
Древовидная сортировка - способ сортировки массива элементов - реализуется в виде простой программы, использующей деревья поиска. Идея заключается в занесении всех элементов в дерево поиска и затем в интерактивном удалении наименьшего элемента до тех пор, пока не будут удалены все элементы. Программа heapSort(пирамидальная сортировка) сортирует массив s из n элементов, используя функцию сравнения cmp:
template void heapSort (T s[], int n, int(*cmp) (T,T) )
{
SearchTree t(cmp);
for (int i = 0; i < n; i++)
t.insert(s[i]);
for (i = 0; i < n; i++)
s[i) = t.removeMin();
}
Также доступна реализация двоичного дерева на Си с базовыми функциями. Операторы typedef T и compGT следует изменить так, чтобы они соответствовали данным, хранимым в дереве. Каждый узел Node содержит указатели left, right на левого и правого потомков, а также указатель parent на предка. Собственно данные хранятся в поле data. Адрес узла, являющегося корнем дерева хранится в укзателе root, значение которого в самом начале, естественно, NULL. Функция insertNode запрашивает память под новый узел и вставляет узел в дерево, т.е. устанавливает нужные значения нужных указателей. Функция deleteNode, напротив, удаляет узел из дерева (т.е. устанавливает нужные значения нужных указателей), а затем освобождает память, которую занимал узел. Функция findNode ищет в дереве узел, содержащий заданное значение.
1 2 3 4
8 8 8
| |